
Legal AI Quality vs. Human Errors
Table of contents
A timely discussion on the measurability of AI systems in the legal field.
The content of this article comes from the webinar "Legal AI Talk: AI Quality vs. Human Errors" held on August 28, 2024, with Dr. Nils Feuerhelm, Director Legal of Libra AI, Dr. Don Tuggener, Research Assistant at ZHAW, Gordian Berger, CTO of Legartis, and David A. Bloch, CEO of Legartis. The conversation was transcribed and slightly summarized.
Legal AI Quality - A Brief Introduction
Artificial Intelligence has been a hotly debated topic at least since the release of ChatGPT. Alongside the capabilities of AI, the question of AI quality is particularly often the focus: How good is it really? And above all: How can it be measured at all? These questions are not only relevant to the technology community but also to companies looking to buy such solutions. After all, as a buyer, you want to know what you're getting into. But do you really have to be able to assess the quality yourself? Or is that even possible? Nils, Don, Gordian, and David get to the bottom of these questions.
What is Meant by the Measurability of AI Models?
Don: Artificial intelligence and machine learning existed before ChatGPT. Evaluating or measuring the performance of an AI has been a concern for a long time. I’ll explain a standard procedure for measuring AI performance: we assume a specific legal task. Let's say you want to extract the jurisdiction from a contract. You start by assigning this task to people and having them solve it. For example, you give 100 contracts to lawyers and ask them, "Please extract the jurisdiction." You then collect the human responses, effectively creating a test set.
Next, you develop an AI for lawyersand give it the same contracts that you gave to the people, asking it the same task: "Please extract the jurisdiction." The AI solves this problem, and you compare its answers with those of the human participants. This gives you a match or deviation, which you can quantify to determine how well the AI performs compared to humans. That's a basic approach.
Nils: I have looked at the whole thing from a legal perspective. There is also the Legal Bench Project, which is currently active mainly in English-speaking countries, such as the UK and the USA. The idea is to test large language models on legal questions. I have started working on a dataset by using my old index cards to create multiple-choice questions — one correct answer and three wrong ones. I then gave these to the models to see if they could find the right answer, for example, on classic civil law questions.
With multiple choice, you can easily determine a score because you can clearly distinguish between right and wrong. The number of correct answers then gives the score. However, it becomes more complex in the legal field. That's also the approach of the Legal Bench Project, and it would be exciting to see this develop for the German-speaking legal market.
The project has formed six categories focusing on different legal tasks: from issue spotting — recognizing legal issues in a given scenario — to recalling and applying rules, drawing conclusions based on rules, and interpreting legal texts, such as extracting relevant information and understanding arguments. These are all different types of tasks that we as lawyers can break down to a very deep level to see which tasks we actually perform as lawyers and how well the model performs in each category.
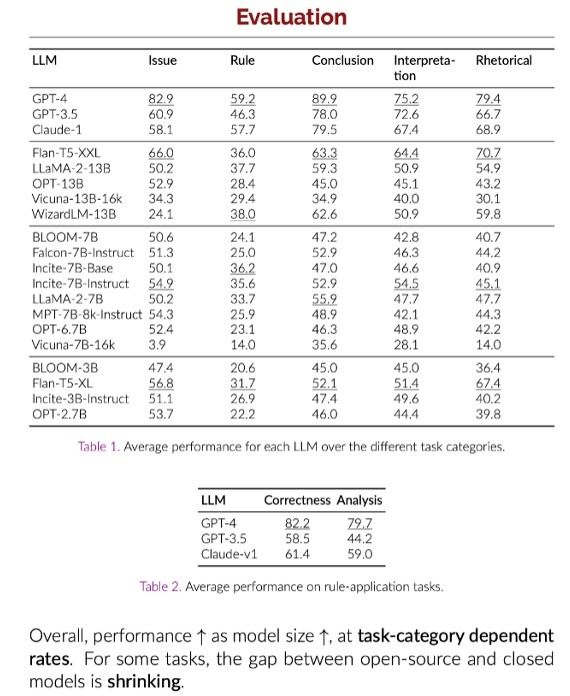 Figure 1 The evaluation shows a table with the categories "Issue," "Rule," "Conclusion," "Interpretation," and "Rhetorical." Interestingly, GPT-4 is at the top here. For the German market, it would be extremely exciting to try this with German data and a German test set. I am currently working on this and looking to establish a benchmark for the German-speaking legal area. After all, new models from Claude or Llama are constantly coming onto the market, and it would be helpful to discuss how they actually perform. It is often simply said: "The new model is better." But that can also mean that GPT-4 is worse in some areas than other models. That is a blanket statement that does not always apply. We need to look more closely, and perhaps we need a German Legal Bench Project for that.
Figure 1 The evaluation shows a table with the categories "Issue," "Rule," "Conclusion," "Interpretation," and "Rhetorical." Interestingly, GPT-4 is at the top here. For the German market, it would be extremely exciting to try this with German data and a German test set. I am currently working on this and looking to establish a benchmark for the German-speaking legal area. After all, new models from Claude or Llama are constantly coming onto the market, and it would be helpful to discuss how they actually perform. It is often simply said: "The new model is better." But that can also mean that GPT-4 is worse in some areas than other models. That is a blanket statement that does not always apply. We need to look more closely, and perhaps we need a German Legal Bench Project for that.
Where Are the Challenges in the Context of AI Measurability?
Don: One difficulty — and there are, of course, many difficulties — is, for example, the complexity of tasks. The more complex the task, the more difficult the evaluation becomes. If I say, for instance, that I want to extract the jurisdiction from a contract, I can easily compare that. A human answer can be compared quite well to a machine answer because it's just a location, and that can be statistically substantiated over many examples.
But when it comes to tasks where the output is not so clear — like summarizing a court case — the evaluation is not as straightforward. It is difficult to determine whether an answer is correct, whether there are multiple correct answers, and what deviations are acceptable. If I ask two people to summarize a court case, I get two different answers. Then you have to discuss which one is better or whether one is even wrong. The same problem exists with AI. If I ask ChatGPT or another model to write a summary, it is anything but trivial to evaluate, especially in an automated way and compared to human summaries.
David: This shows how much knowledge is needed to evaluate the quality of an AI model and how deeply you have to engage with the subject.
Why Should a User Understand the Quality of an AI Model?
Gordian: This is one of the big challenges right now. You can go into even more detail.
As a user, it is not enough just to use some test or official benchmark without really knowing what quality is being tested. I think as a user, you must understand which business case you want to solve with AI, as every business case can be evaluated differently.
In the Legal Benchmark graphic, we could already see this quite well: There was not just one score but several, depending on the use case. In the business field, it's even more complicated because the use case can be very concrete and specific. This means that as a user, you first need to know how precise you need to be to do daily business and how accurate the AI must be. The same applies to AI errors.
Take contract review, for example. As a user, you need to consider: Is it worse if the AI identifies potential risks too often or if it fails to detect a risk? Depending on that, you can optimize the AI's errors differently. That's something you need to know when using AI. That's the challenge.
Of course, you can also hope that the available tools will partially solve this problem for you. We also see this challenge as providers. At Legartis, we make AI decisions visible when the customer reviews a contract. It's about knowing why the AI made a particular decision so that errors can be identified and corrected iteratively.
Don: Ultimately, it's also about recognizing whether it's even an error or more of a misunderstanding. With many tools today, it's not just about the AI itself but also about the prompts. There are tools where users can define their prompts and pass their requests to the AI, which then acts automatically. This can easily lead to misunderstandings that affect quality. It's also worth testing your prompts to ensure.
Which Types of AI Errors Are Tolerable and Which Are Not?
Nils: When generally speaking of lawyers, it depends, of course, on the area of law and the type of task. I would say there are distinctions to be made. In business law, in my opinion, most areas are not so highly sensitive, but that varies. I would differentiate between the area of law and the type of task: Will there be a subsequent review by a human, i.e., a manual review? Or is it just an initial assessment, or do we have an almost autonomously running, AI-controlled task where no one looks at it anymore, or at least not in detail? In such cases, errors are less forgivable; the error rate must be close to zero.
Gordian also pointed out the type of errors: Is the answer incomplete or inaccurate? That is also a type of error in the legal field. Or do we have a serious problem, such as an overlooked risk? Personally, I think it's better to flag one risk too many than one too few. As a lawyer, you should always choose the safest way, and I would also see it that way for AI. In case of doubt, it is better to flag more than too little.
Currently, I see that AI is primarily used for contract review and clause checking. It is used in preliminary work, where a lawyer still looks over it at the end. You might let it draft the first email or the first draft of a pleading. That means AI supports preliminary work, but in the end, you still check it over, adjust the wording, and send the email yourself. I would say that errors are forgivable if something isn't quite right.
However, when we get into areas where maybe no one is looking over it anymore, you have to ensure that no errors occur through good evaluation, performance, and assurance of AI quality. Ultimately, it comes down to how much trust you can put in the AI.
Don: Yes, that's a good point. It's a lot about building the trust needed to delegate tasks to an AI, as you said, Nils. The question is: What kind of errors does the AI make compared to humans? Take a summary, for example: If the AI creates a summary and weights certain aspects differently than a human or omits certain things because they don't seem that important in the context, you could also say: That's a different interpretation or opinion. But if the AI suddenly starts inventing things that aren't in the source document at all — that's called "hallucinating" — it becomes uncomfortable.
I think people are more willing to accept AI errors if it makes similar mistakes to us or presents things differently but still seems plausible. It's easier to trust the AI if it stays within this frame. But if the machine does something completely unexpected and unpredictable, it becomes harder to build trust.
Is There a Measurement System That Evaluates Human Performance Compared to AI?
Don: It really depends on the problem. Deviations are not always errors; sometimes, they're just different interpretations or solutions or answers that are all legitimate. For tasks like extracting the jurisdiction, you can measure how good an AI is fairly reliably. But even for simpler tasks, humans make mistakes. If, for example, they annotate data or go through hundreds of contracts for hours extracting jurisdictions, mistakes can also happen. The question then is: What do we expect from an AI if humans are also fallible?
Nils: Fundamentally, of course, lawyers don't make mistakes ;-), but it does happen occasionally. You've already mentioned it, Don. There are also studies showing that for repetitive tasks, like going through contracts for hours and picking out clauses, the work isn't fun. Often, younger staff, such as associates, are employed to do these simple tasks. And there are indications that LLMs perform better than associates or juniors. Because if I have to read contracts all day and filter out clauses or structure a data room, fatigue sets in at some point. An AI can offer incredible advantages if it is tested in advance.
From a lawyer's perspective, we are also insured against professional errors. Lawyers basically don't make mistakes, but if they do, professional liability insurance kicks in. It gets interesting when we ask in which area this insurance applies, especially when it comes to the use of AI. When exactly is the professional activity of a lawyer covered by insurance if I, as a lawyer, use AI? This discussion is currently ongoing.
Don also touched on the topic of trust: If I train someone and consider the AI as an employee in a way, you could say that you trust it at some point. You don't check everything every time but rely on the work being good because it has proven itself 15, 20, or 25 times. With the AI, I might not check 20 times but 200 or 2000 times to see if the result is correct. If, after 2000 times, I see that the AI works well and reliably, trust builds up, and I would accept the results.
In the end, it's a risk assessment, both for humans and AI. For AI, we must weigh more heavily, but if it proves itself, you can delegate the decision. If an error still happens, liability insurance applies.
What Perspective on AI Quality vs. Humans Exists from a Product Perspective?
Gordian: Yes, part of my perspective aligns with what Nils said, especially when it comes to full automation: It's a lot about balancing risk and efficiency. But there is also another perspective, which is the combination of AI and humans. I believe this is the level AI is currently at. It may not be so important for the current business case to evaluate the AI against humans. Perhaps it makes more sense to say the AI supports the human and already provides so much added value that the benchmark should be set that way: human plus AI vs. a human working alone. I think that's what we're currently seeing with most tools, not only in the legal field but also in others. The AI is a very good assistant in many areas and often beats a human working without that assistance. I think our customers and the industry agree that we are roughly at this stage.
Is It No Longer Appropriate Today to Perform Tasks Like Due Diligence Without AI?
Gordian: I would say that since everyone is still a bit slow, you still have time not to miss the train. But you already have a disadvantage in cost optimization if you don't use AI. AI assistance can counteract the shortage of skilled workers quite a bit.
Don: The point — AI together with a human — is extremely important. We see that AI works well and reliably for modern, boring tedious tasks because the task area is limited. The great thing is that it takes away the tedious work from AI lawyers so they have more time for the really demanding tasks where they are the experts. I see only advantages there.
Nils: Perhaps another perspective: In the long term, those who do not use AI will look like someone who still uses paper files and doesn't have a document management system. It all still works, but in the long run, it will be less and less accepted. A big problem — and I don't want to open it up completely — is the "billable hour." Efficiency is not currently rewarded. In the end, I just want to bill more. It doesn't matter if I need three hours for a mandate or if I do three mandates in the same time. If I have the same hourly rates, it doesn't matter. But I think what's coming is that no one will accept spending eight hours on a contract review.
I hope this changes quickly because that's also the reason for the lack of tech affinity among lawyers. Innovation is only conditionally rewarded by the billing models we currently have. If this changes — and the pressure will come from clients, in my opinion — then the market will change. We're already seeing this: Pitches from big law firms are already different. Contingencies are agreed upon, and it's clearly structured in advance. Lawyers have to make sure they can do the work within the agreed framework. Otherwise, they lose money, and then it becomes exciting because tools have to be used. And we can already see that this will prevail, especially when clients don't open the account quite as wide anymore. This will start with the big law firms, but I think it will also spread to medium-sized and smaller firms.
David: The use of AI has a lot to do with trust — this has been mentioned several times. This trust has to be built. In other areas and industries, there are already quality standards, such as the TÜV (Technical Inspection Association).
Would It Help Users in the AI Field If There Were Quality Standards, Like TÜV, to Make Everything Comparable?
Don: You have to differentiate between what exactly is meant by standards or measurability. Many standards, like those from TÜV, ensure that a product or machine meets certain safety standards, such as withstanding a certain weight. It would be desirable if there were such safety standards in the field of artificial intelligence — for example, concerning hallucinations or other safety precautions. That would help me sleep more soundly when using AI because I would know it wouldn't make catastrophic errors.
But that doesn't help me choose the best solution for my specific use case among the existing AI solutions. Just because an AI doesn't make catastrophic errors in other contexts doesn't mean it's the best solution for my specific case. So these standards help only partially or not at all in choosing a specific solution. For that, you need specific tests tailored to your particular problem.
Nils: Yes, I see performance similarly to Don. I know that law firms have licenses for almost all large language models to experiment with them. I know they have already built tests internally, as we discussed earlier, but individually for their respective practice group to see if it works. Testing is already happening, and I also think you still need to adapt it to the individual task. You can improve quality through prompting and some control within specific tasks in law firms or legal departments.
Standards in terms of data protection and data security are, of course, essential — we don't need to discuss that. But measuring performance for the individual use case is more complex. You could perhaps create a comparison website like Check24 for the best contract review AI, but that would really have to be tailored to the use case. I also see problems there, for example: A general terms and conditions (AGB) checker would be problematic to compare because there are so many different use cases — such as a solar company versus a software company. If you build a tool for AGB checking or drafting and want to measure performance here, the wide range in the legal field gets in the way. That makes it so difficult to set standards regarding performance.
If I Want to Select an AI Solution as a User — How Do I Proceed?
Gordian: There are two perspectives: Do I want to select a finished solution or develop it myself? In both cases, you must ensure that the process we talked about is followed. This means, first, you have to define what the business case is. Is full automation sensible, or rather support by AI? How good must the AI be for this specific business case?
Of course, there are also general topics like data security and accuracy regarding your business case. It is also important that you have the necessary expertise to evaluate the business case. You can't just let the development team and the AI team run wild. You need the know-how, for example, of lawyers who review contracts to know exactly how to do it. Only if the specialist department and the AI department work together will a meaningful result come out.
The same applies when selecting an out-of-the-box solution. There are already some standards, such as ISO certifications, but no fully covered process. When selecting a provider, I would do a kind of plausibility check: I would ask the provider directly how they ensure quality, whether they have specific tests for the respective use case, and whether there are actually lawyers in the team in the Legal Tech area who can ensure quality. In my opinion, a Legal Tech provider without a lawyer on the team is not trustworthy. You really have to do this plausibility check to see if the provider can actually deliver.
David: So, one should ask about the AI, how the provider deals with the issue of test sets, and pay attention to how the team is composed — are only technicians on board, only lawyers, or a combination?
Gordian: Exactly. And the same assessment should, of course, be done internally if it is to be a successful project. But it's just as important to do this with the provider. Currently, there are many players on the market due to the hype, who have put something together relatively quickly with a few people and ChatGPT. Whether that can ensure quality in the long term is questionable. You have to see if the team is really able to deliver the necessary performance. In my opinion, a provider can only ensure that if they also have experts on the team.
Nils: I completely agree with Gordian. A good example is Harvey — they received a lot of money, and the first thing they did was poach people from large law firms at the partner level who have the necessary knowledge or can at least act at the general counsel level. You need someone who can professionally evaluate both the input and the output. None of us really know at some point whether the clause in an M&A contract fits or not; I've never done that, so I'm completely out of it, just like with outputs from other areas of law. You need experts on the team who can assess the output from a legal perspective. That's crucial in the end. Of course, an internal evaluation also takes place, but team structure is a very important point.
Don: It is important to have a standardized process to evaluate an AI solution so that different solutions can be compared. In principle, we already know this problem from our everyday lives — we hear about new AI tools every day and wonder if we should use them. Many people have prepared a few sample requests, sometimes only two or three, to test whether the AI can solve these specific problems. The same must be done at the business level: you have to decide what is important to you and compile the appropriate test sets. Ideally, this should be automated because it's impractical to spend hundreds of hours on annotations, evaluation time, and resources every time a new tool comes out. It's not easy to find an efficient protocol that delivers meaningful results, but it's definitely worth it to stay competitive and quickly deploy new solutions.
David: So it essentially comes down to creating test sets — either yourself or in collaboration with a provider who approaches it in a structured way and can assess which language model is best suited for which task. If, as a user, there is no explainability or transparency about how the whole thing is approached, you should be skeptical, right?
Don: Absolutely. Even if internal test sets are used, I also have to be able to assess how well these test sets fit my use case. If, for example, it's about finding clauses, that's a different use case than evaluating entire court cases. Just getting information from the provider doesn't say much about how well the solution covers my specific case.
David: Inevitably, I see the challenge that the awareness of what one actually wants to do is often not yet present with many customers looking for AI products. They just look around to see what's available but do not engage with quality because they don't clearly know which problem they want to solve. That doesn't work that way. Or do you see it differently?
Don: That could also work if I, as a provider, show you: We know that the same problems keep coming up in various law firms, and we have developed a solution for that. Maybe that's not a problem in your firm, so you're not interested, but we can offer standardized solutions.
Nils: AI is not an end in itself. In my view, AI is currently primarily an opportunity for law firms and legal departments to engage with new tools. Maybe they didn't need it before, but that shouldn't be the only reason. Generally, it is good for digitalization projects to look at new technologies and check whether there are opportunities for use. But that shouldn't be done at any cost. If I have a specific use case, I should first consider where it makes sense to integrate AI into my processes. Blindly buying something just because everyone else is doing it is not sensible. Sometimes this is driven by FOMO (Fear of Missing Out), just because others are doing it. It is better to invest time and money selectively.
David: Thank you very much for the interesting insights — many thanks to Nils, Don, and Gordian!
Learn how Legartis accelerates your contract work with AI.

Questions from the Audience
How much faster are you if AI does the preliminary work, such as contract review, and this preliminary work is then manually corrected?
Gordian: Yes, that's a very good question. It goes exactly in the direction we've already discussed. The use of AI, as we see, for example, at Legartis in contract review, means that AI serves as an assistant solution. It helps get the work done faster. We look closely at how much time a manual review takes and how much time a review with AI takes. In most cases, you are significantly faster with AI and have a reduced error rate at the same time.
David: There are also use cases like due diligence. If you have to search through 1,000 contracts for certain questions, it inevitably takes longer if you do it manually than if you use a Legal AI for legal analytics. In this context, AI can really do great preliminary work.
How is liability regulated if AI makes mistakes, and what consequences could arise from this?
Nils: The question is generally formulated, but fundamentally, I would say: If I, as a lawyer, issue a pleading, it ultimately doesn't matter how this pleading was created — whether I wrote it myself or used AI for it. As soon as I put my name on it and send the document under my name, I am liable for it. Therefore, in the case of AI errors, it is essentially the same as for all other technical tools I use beforehand. There is generally the possibility of insuring against errors, but it also depends on how the AI is used and which tool is used. But fundamentally, I would say: In the mere creation of pleadings, whether around contracts or the like, liability ultimately remains with the lawyer who signs it.
Are there parallels to error tolerance in autonomous driving? Are we more tolerant of human errors than of AI tools?
Don: That's not so easy to judge. In autonomous driving, there are these classic ethical dilemmas. Some car manufacturers have already gone out on a limb with questions like: "If the car is heading toward a pedestrian, what do I do? Can I brake in time, or do I drive into a wall and endanger the driver?" These are serious problems. The question is: Are clients more tolerant of lawyer errors than AI errors? I can't judge that directly because you, Gordian and Nils, probably have more customer contact and can say better how people react when the AI or the solutions we present make mistakes.
Gordian: It's not easy to answer, but I do see parallels. Clients tend to be more critical of AI because the errors are often more visible than those of humans. If a junior lawyer makes a mistake, you don't always see it immediately. But with AI, the errors are directly visible.
Nils: I see it similarly. Lawyers and legal professionals are generally very critical of the output of software solutions, which is good but sometimes also challenging for us as providers. Ultimately, healthy skepticism is not wrong, especially as we increasingly rely on more autonomous systems. It is important for everyone to engage with AI to understand where the errors could be and how to fix them. This broadens understanding. Understanding that the error does not necessarily lie with the AI, but for example, with the lack of data because I did not obtain it because something is incomplete in my documents. Understanding this and not just having blind skepticism but understanding with background knowledge where the error could be is very important. I think there will still be a lot of movement. The solutions will get better because the providers, of course, learn from the feedback and can improve their systems accordingly.
Learn how Legartis accelerates your contract work with AI.

Explore Related Insights
More articles related to this topic

“Everyone should get involved with LegalTech before its development leaves them behind”
Start withLegartis Today!
Talk to us about your business case or test Legartis right away!