
Legal AI-Qualität vs. menschliche Fehler
Inhaltsverzeichnis
Die Inhalte dieses Artikels stammen aus dem Webinar "Legal AI Talk: AI-Qualität vs.
Die Inhalte dieses Artikels stammen aus dem Webinar "Legal AI Talk: AI-Qualität vs. menschliche Fehler" vom 28.8.2024 mit Dr. Nils Feuerhelm, Director Legal von Libra AI, Dr. Don Tuggener, Research Assistant ZHAW, Gordian Berger, CTO Legartis, David A. Bloch, CEO Legartis. Das Gespräch wurde transkribiert und leicht zusammengefasst worden. Bei Interesse können Sie auch einfach das Recording anschauen oder anhören.
Legal AI-Qualität - eine kurze Einführung
Künstliche Intelligenz ist spätestens seit dem Release von ChatGPT ein heiss diskutiertes Thema. Neben den Fähigkeiten von KI steht besonders die Frage nach der AI-Qualität immer wieder im Fokus: Wie gut ist sie wirklich? Und vor allem: Wie lässt sich das überhaupt messen? Diese Fragen sind nicht nur für die Technologie-Community relevant, sondern auch für Unternehmen, die solche Lösungen kaufen wollen. Als Käufer oder Käuferin will man schliesslich wissen, worauf man sich einlässt. Aber muss man denn wirklich die Qualität selbst beurteilen können? Oder kann man das überhaupt? Genau diesen Fragen gehen Nils, Don, Gordian und David auf den Grund.
Was wird unter Messbarkeit von KI-Modellen verstanden?
Don: Künstliche Intelligenz und Machine Learning gab es ja schon vor ChatGPT. Wie man die Leistung einer KI evaluiert oder misst, beschäftigt uns schon seit langer Zeit. Ich erläutere ein Standardverfahren, wie man die KI-Leistung messen kann: Wir gehen davon aus, dass man eine bestimmte juristische Aufgabe hat. Sagen wir, man möchte aus einem Vertrag den Gerichtsstand extrahieren. Dann geht man so vor, dass man als Erstes Menschen diese Aufgabe überträgt und sie lösen lässt. Man gibt zum Beispiel 100 Verträge an Juristen und sagt ihnen: "Bitte extrahiert mir den Gerichtsstand." Dann sammelt man die Antworten der Menschen und hat so de facto ein Testset erstellt.
Nun entwickelt man eine KI und gibt ihr genau die gleichen Verträge, die man auch den Menschen gegeben hat, und stellt die gleiche Aufgabe der KI: "Bitte extrahiere den Gerichtsstand." Die KI löst dann dieses Problem und man vergleicht die Antworten der KI mit denen der menschlichen Teilnehmenden. So erhält man eine Übereinstimmung oder Abweichung und kann quantifizieren, wie gut die KI im Vergleich zu den Menschen eine Aufgabe lösen kann. Das ist eine grundlegende Herangehensweise.
Nils: Ich habe mir das Ganze mal aus juristischer Perspektive angeschaut. Es gibt dazu auch das Legal Bench Project. Das ist aktuell vor allem im englischsprachigen Raum, also in Grossbritannien und den USA, aktiv. Die Idee ist, Large Language Models auf juristische Fragestellungen zu testen. Ich habe angefangen, an einem Datenset zu arbeiten, indem ich meine alten Karteikarten dazu genutzt habe, um Multiple-Choice-Fragen zu erstellen, also eine richtige Antwort und drei falsche. Diese habe ich dann den Modellen gegeben, um zu sehen, ob sie die richtige Antwort finden, zum Beispiel bei klassischen BGB-AT-Fragen.
Mittels Multiple Choice kann man relativ einfach einen Score ermitteln, weil man klar zwischen richtig und falsch unterscheiden kann. Die Anzahl der richtigen Antworten ergibt dann den Score. Im juristischen Bereich wird es allerdings etwas komplexer. Das ist auch der Ansatz des Legal Bench Projects, und es wäre spannend, das Ganze auch für den deutschsprachigen Rechtsmarkt zu sehen und weiterzuentwickeln.
Das Projekt hat sechs Kategorien gebildet, die sich auf verschiedene juristische Aufgaben konzentrieren: vom Issue Spotting, also dem Erkennen rechtlicher Fragen in einem Sachverhalt, über das Abrufen und Anwenden von Regeln, Schlussfolgerungen auf Basis von Regeln, bis hin zur Interpretation juristischer Texte, also der Extraktion relevanter Informationen und dem Verständnis von Argumenten. Das sind alles unterschiedliche Arten von Aufgaben, die wir als Juristen auf eine ganz tiefe Ebene herunterbrechen können, um zu sehen, welche Aufgaben wir als Anwälte oder Juristen eigentlich erfüllen und wie gut das Modell in den jeweiligen Kategorien performt.
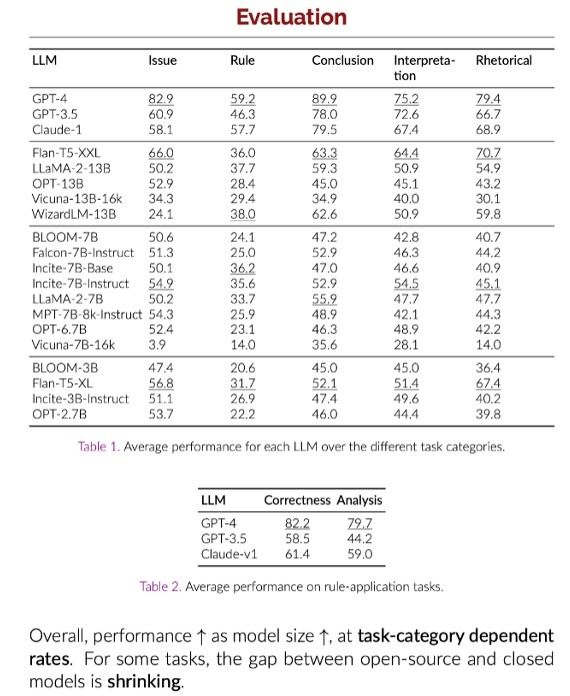 Abbildung 1 : In der Evaluation sehen wir eine Tabelle mit den Kategorien "Issue", "Rule", "Conclusion", "Interpretation" und "Rhetorical". Interessanterweise steht GPT-4 hier ganz weit oben. Für den deutschen Markt wäre es natürlich extrem spannend, das mal mit deutschen Daten und einem deutschen Testset auszuprobieren. Daran arbeite ich momentan auch und schaue, ob wir eine Benchmark für den deutschsprachigen Rechtsraum schaffen können. Schliesslich kommen ständig neue Modelle von Claude oder Llama auf den Markt, und es wäre hilfreich, darüber sprechen zu können, wie sie tatsächlich performen. Aktuell heisst es oft einfach: "Das neue Modell ist besser." Aber das kann auch bedeuten, dass GPT-4 in manchen Bereichen sogar schlechter ist als andere Modelle. Das ist eine pauschale Aussage, die nicht immer zutrifft. Wir müssen genauer hinschauen, und dafür brauchen wir vielleicht ein German Legal Bench Projekt.
Abbildung 1 : In der Evaluation sehen wir eine Tabelle mit den Kategorien "Issue", "Rule", "Conclusion", "Interpretation" und "Rhetorical". Interessanterweise steht GPT-4 hier ganz weit oben. Für den deutschen Markt wäre es natürlich extrem spannend, das mal mit deutschen Daten und einem deutschen Testset auszuprobieren. Daran arbeite ich momentan auch und schaue, ob wir eine Benchmark für den deutschsprachigen Rechtsraum schaffen können. Schliesslich kommen ständig neue Modelle von Claude oder Llama auf den Markt, und es wäre hilfreich, darüber sprechen zu können, wie sie tatsächlich performen. Aktuell heisst es oft einfach: "Das neue Modell ist besser." Aber das kann auch bedeuten, dass GPT-4 in manchen Bereichen sogar schlechter ist als andere Modelle. Das ist eine pauschale Aussage, die nicht immer zutrifft. Wir müssen genauer hinschauen, und dafür brauchen wir vielleicht ein German Legal Bench Projekt.
Wo gibt es Herausforderungen im Kontext der KI-Messbarkeit?
Don: Eine Schwierigkeit – und es gibt natürlich viele Schwierigkeiten – ist zum Beispiel die Komplexität der Aufgaben. Je komplexer die Aufgabe, desto schwieriger wird die Evaluation. Wenn ich zum Beispiel sage, ich möchte den Gerichtsstand aus einem Vertrag extrahieren, dann kann ich das relativ einfach abgleichen. Eine menschliche Antwort kann ich mit einer maschinellen Antwort recht gut vergleichen, da es sich nur um eine Ortsangabe handelt, und das kann man über viele Beispiele hinweg statistisch untermauern.
Aber wenn es um Aufgaben geht, bei denen der Output nicht so klar ist – zum Beispiel die Zusammenfassung eines Gerichtsprozesses –, dann ist die Bewertung nicht so eindeutig. Es ist schwierig zu bestimmen, ob eine Antwort richtig ist oder ob es mehrere richtige Antworten gibt und welche Abweichungen man überhaupt zulassen kann. Wenn ich zwei Menschen bitte, eine Zusammenfassung eines Gerichtsprozesses zu schreiben, bekomme ich auch zwei unterschiedliche Antworten. Da muss man dann diskutieren, welche besser ist oder ob eine überhaupt falsch ist. Dasselbe Problem habe ich mit KI. Wenn ich ChatGPT oder ein anderes Modell bitte, eine Zusammenfassung zu schreiben, ist es alles andere als trivial, diese zu evaluieren, besonders automatisiert und im Vergleich zu menschlichen Zusammenfassungen.
David: Das zeigt schon, wie viel Wissen notwendig ist, um die Qualität eines KI-Modells zu bewerten und wie tief man sich mit der Materie auseinandersetzen muss.
Warum sollte ein Nutzer*in die Qualität eines KI-Modells verstehen?
Gordian: Das ist tatsächlich eine der grossen Herausforderungen aktuell. Man kann da auch noch tiefer ins Detail gehen. Als Nutzer*in ist es nicht ausreichend, einfach irgendeinen Test oder ein offizielles Benchmark zu verwenden, ohne wirklich zu wissen, welche Qualität dabei tatsächlich geprüft wird. Was ich damit meine: Ich denke, als Nutzer*in muss man verstehen, welchen Business Case man mit der KI lösen möchte, denn jeder Business Case kann unterschiedlich bewertet werden.
In der Grafik von Legal Benchmark hat man das schon ganz gut gesehen: Es gab nicht nur einen Score, sondern verschiedene, je nach Use Case. Im Business-Bereich ist das noch komplizierter, weil der Use Case sehr konkret und spezifisch sein kann. Das heisst, als Nutzer muss man zunächst wissen, wie genau man selbst sein muss, um das tägliche Geschäft zu erledigen, und wie genau die KI sein muss. Dasselbe gilt für die Fehler der KI.
Nehmen wir zum Beispiel die Vertragsprüfung. Als Nutzer muss man sich überlegen: Ist es schlimmer, wenn die KI zu häufig potenzielle Risiken erkennt, oder wenn sie ein Risiko nicht erkennt? Je nachdem kann man die Fehler der KI unterschiedlich optimieren. Das ist etwas, was man als Nutzer wissen muss, wenn man KI einsetzt. Das ist die Herausforderung.
Man kann natürlich auch hoffen, dass die Tools, die bereits verfügbar sind, einem dieses Problem teilweise abnehmen. Diese Herausforderung sehen wir natürlich auch als Anbieter. Bei Legartis machen wir die KI-Entscheidungen sichtbar, wenn der Kunde einen Vertrag prüft. Es geht darum, zu wissen, warum die KI eine bestimmte Entscheidung getroffen hat, damit man Fehler identifizieren und iterativ korrigieren kann.
Don: Letztlich geht es auch darum zu erkennen, ob es überhaupt ein Fehler ist oder eher ein Missverständnis. Bei vielen Tools heute geht es ja nicht nur um die KI selbst, sondern auch um die Prompts. Es gibt Tools, mit denen man als Nutzer selbst Prompts definieren und seine Wünsche der KI übergeben kann, die dann automatisiert agiert. Dabei kann es leicht zu Missverständnissen kommen, die die AI-Qualität beeinträchtigen. Auch für die eigenen Prompts bietet es sich an, diese zu testen, um die Qualität sicherzustellen.
Welche Arten von KI-Fehlern sind tolerierbar und welche nicht?
Nils: Wenn man allgemein von Juristinnen und Juristen spricht, kommt es natürlich auf das Rechtsgebiet und die Art der Aufgabe an. Ich würde sagen, es gibt Unterscheidungen, die man treffen muss. Im Wirtschaftsrecht sind meiner Meinung nach die meisten Bereiche nicht so hochsensibel, aber das ist natürlich unterschiedlich. Ich würde zwischen Rechtsgebiet und Art der Aufgabe unterscheiden: Gibt es später eine Überprüfung durch einen Menschen, also einen manuellen Review? Oder ist es nur eine Ersteinschätzung, oder haben wir eine nahezu autonom laufende, KI-gesteuerte Aufgabe, bei der niemand mehr darüber schaut, oder zumindest nicht im Detail? In solchen Fällen sind Fehler weniger verzeihlich; da muss die Fehlerquote nahe null liegen.
Gordian hat auch auf die Art der Fehler hingewiesen: Ist die Antwort unvollständig oder ungenau? Das ist auch eine Art Fehler im juristischen Bereich. Oder haben wir eine gravierende Problematik, wie zum Beispiel ein übersehenes Risiko? Ich persönlich finde, es ist besser, wenn ein Risiko zuviel markiert wird als eins zu wenig. Als Anwalt sollte man immer den sichersten Weg wählen, und das würde ich auch für die KI so sehen. Im Zweifel lieber mehr markieren als zu wenig.
Aktuell sehe ich, dass KI vor allem bei der Contract Review und der Klauselprüfung eingesetzt wird. Also bei Vorarbeiten, bei denen am Ende nochmal ein Anwalt drüber schaut. Man lässt sich vielleicht die erste E-Mail formulieren oder einen ersten Schriftsatzentwurf schreiben. Das heisst, die KI unterstützt bei den Vorarbeiten, aber am Ende schaut man trotzdem noch einmal darüber, passt Formulierungen an und schickt die E-Mail dann selbst ab. Da würde ich sagen, sind Fehler verzeihbar, wenn etwas nicht ganz genau stimmt.
Wenn wir jedoch in Bereiche kommen, wo möglicherweise niemand mehr darüber schaut, muss man durch gute Evaluation, Performance und Sicherstellung der KI-Qualität sicher sein, dass dort keine Fehler passieren. Letztendlich läuft es darauf hinaus, wieviel Vertrauen man in die KI setzen kann.
Don: Ja, das ist ein guter Punkt. Es hat viel mit Vertrauen zu tun, das man aufbauen muss, um Aufgaben an eine KI zu übergeben, wie du es auch gesagt hast, Nils. Die Frage ist dann: Welche Art von Fehlern macht die KI im Vergleich zum Menschen? Nehmen wir als Beispiel eine Zusammenfassung: Wenn die KI eine Zusammenfassung erstellt und dabei gewisse Aspekte anders gewichtet als ein Mensch oder bestimmte Dinge auslässt, weil sie in dem Kontext nicht so wichtig erscheinen, könnte man auch sagen: Das ist eine andere Interpretation oder Meinung. Aber wenn die KI plötzlich beginnt, Dinge zu erfinden, die im Ausgangsdokument gar nicht stehen – das nennt man dann "halluzinieren" – wird es unangenehm. Ich denke, Menschen sind eher bereit, KI-Fehler zu akzeptieren, wenn sie ähnliche Fehler macht wie wir oder Dinge anders darstellt, die aber noch plausibel erscheinen. Es ist einfacher, Vertrauen in die KI zu haben, wenn sie sich in diesem Rahmen bewegt. Wenn die Maschine jedoch etwas komplett Unerwartetes und Unvorhersehbares macht, dann ist es schwieriger, Vertrauen aufzubauen.
Gibt es ein Messsystem, das die Leistungen von Menschen im Vergleich zu KI bewertet?
Don: Das hängt wirklich vom Problem ab. Abweichungen sind nicht immer Fehler; manchmal sind es einfach unterschiedliche Interpretationen oder Lösungen oder Antworten, die alle ihre Berechtigung haben. Bei Aufgaben wie der Extraktion des Gerichtsstands kann man ziemlich zuverlässig messen, wie gut eine KI ist. Aber auch bei einfacheren Aufgaben machen Menschen Fehler. Wenn sie beispielsweise Daten annotieren oder stundenlang hunderte Verträge durchgehen und Gerichtsstände extrahieren müssen, können auch Fehler passieren. Die Frage ist dann: Was erwarten wir von einer KI, wenn auch Menschen fehlbar sind?
Nils: Grundsätzlich machen Anwälte natürlich keine Fehler ;-), aber es kommt gelegentlich doch vor. Du hast es schon angesprochen, Don. Es gibt ja auch Studien, die zeigen, dass bei repetitiven Aufgaben, wie dem stundenlangen Durchsehen von Verträgen und dem Heraussuchen von Klauseln, die Arbeit keinen Spass macht. Da werden oft jüngere Mitarbeitende wie Associates eingesetzt, um diese einfachen Aufgaben zu erledigen. Und da gibt es Hinweise darauf, dass LLMs besser abschneiden als Associates oder Juniors. Denn wenn ich den ganzen Tag Verträge lesen und Klauseln herausfiltern oder mir einen Datenraum strukturieren muss, kommt irgendwann Ermüdung auf. Eine KI kann hier unglaubliche Vorteile bieten, wenn man sie vorab entsprechend getestet hat.
Aus anwaltlicher Perspektive sind wir auch gegen Beratungsfehler versichert. Anwälte machen also im Grunde keine Fehler, aber wenn doch, dann greift die Berufshaftpflichtversicherung. Spannend wird es, wenn wir uns fragen, in welchem Bereich diese Versicherung greift, vor allem wenn es um den Einsatz von KI geht. Wann genau ist die berufliche Tätigkeit des Anwalts von der Versicherung abgedeckt, wenn ich als Anwalt KI nutze? Diese Diskussion läuft aktuell.
Don hat ja auch das Thema Vertrauen angesprochen: Wenn ich jemanden ausbilde und die KI in gewisser Weise als Mitarbeiter betrachte, könnte man sagen, dass man ihr irgendwann vertraut. Man kontrolliert nicht jedes Mal alles, sondern verlässt sich darauf, dass die Arbeit gut ist, weil sie sich 15, 20 oder 25 Mal bewährt hat. Bei der KI würde ich vielleicht nicht 20 Mal, sondern 200 oder 2000 Mal kontrollieren, ob das Resultat korrekt ist. Wenn ich nach 2000 Mal sehe, dass die KI gut funktioniert und die Arbeit zuverlässig macht, dann baut sich Vertrauen auf, und ich würde die Ergebnisse akzeptieren.
Am Ende ist es eine Risikobewertung, sowohl bei Menschen als auch bei der KI. Bei der KI müssen wir mehr in die Waagschale werfen, aber wenn sich das bewährt, dann kann man die Entscheidung auch abgeben. Sollte dennoch ein Fehler passieren, greift die Haftpflichtversicherung.
Welchen Blickwinkel auf KI-Qualität vs. Mensch gibt es aus Produktsicht?
Gordian: Ja, also ein Teil meiner Perspektive deckt sich natürlich mit dem, was Nils gesagt hat, besonders wenn es um die Vollautomatisierung geht: Da geht es viel um die Abwägung von Risiko und Effizienz. Aber es gibt auch noch eine andere Sichtweise, und das ist die Kombination von KI und Mensch. Ich glaube, auf diesem Niveau ist die gerade. Es könnte für den aktuellen Business Case gar nicht so wichtig sein, die KI gegen den Menschen zu bewerten. Vielleicht macht es mehr Sinn zu sagen, die KI unterstützt den Menschen und bietet dadurch bereits so viel Mehrwert, dass man so den Benchmark legen sollte: Mensch plus KI vs. eines allein arbeitenden Menschen. Ich denke, das sehen wir derzeit bei den meisten Tools, nicht nur im juristischen Bereich, sondern auch in anderen. Die KI ist in vielen Bereichen eine sehr gute Assistenz und schlägt in vielen Fällen einen Menschen, der ohne diese Assistenz arbeitet. Ich glaube, unsere Kunden und die Industrie sind sich einig, dass wir ungefähr auf diesem Stand sind.
Ist es heute nicht mehr angebracht, Arbeiten wie die Due Diligence ohne KI zu erledigen?
Gordian: Ich würde sagen, da aktuell alle noch etwas langsam sind, hat man noch Zeit, den Zug nicht zu verpassen. Aber man hat definitiv schon einen Nachteil in der Kostenoptimierung, wenn man keine KI einsetzt. Gerade dem Fachkräftemangel kann man mit KI-Assistenz einiges entgegenwirken.
Don: Der Punkt – KI zusammen mit dem Menschen – ist extrem wichtig. Wir sehen, dass die KI bei modernen, langweiligen Fleissarbeiten gut und zuverlässig funktioniert, weil der Aufgabenbereich eingeschränkt ist. Das Tolle daran ist, dass sie Anwältinnen und Anwälten die mühsame Arbeit abnimmt, sodass sie mehr Zeit für die wirklich anspruchsvollen Aufgaben haben, bei denen sie die Experten sind. Ich sehe da wirklich nur Vorteile.
Nils: Vielleicht noch eine andere Perspektive dazu: Langfristig wird derjenige, der keine KI nutzt, dastehen wie jemand, der immer noch Papierakten verwendet und kein Dokumentenmanagement-System hat. Das funktioniert zwar noch alles, aber auf längere Sicht wird es immer weniger akzeptiert. Ein grosses Problem – und das möchte ich jetzt nicht ganz aufmachen – ist die "Billable Hour". Es wird derzeit nicht belohnt, effizient zu arbeiten. Am Ende möchte ich einfach mehr abrechnen. Es ist egal, ob ich für ein Mandat drei Stunden brauche oder ob ich drei Mandate in derselben Zeit mache. Wenn ich die gleichen Stundensätze habe, spielt es keine Rolle. Aber ich glaube, was kommen wird, ist, dass niemand mehr acht Stunden für eine Vertragsprüfung akzeptieren wird.
Ich hoffe, dass sich das schnell ändert, denn das ist auch der Grund für die mangelnde Tech-Affinität von Juristen. Die Innovation wird durch die Abrechnungsmodelle, die wir gerade haben, nur bedingt belohnt. Wenn sich das ändert – und der Druck wird meiner Meinung nach von den Mandanten kommen – dann wird sich der Markt verändern. Das sehen wir bereits: Bei Pitches von Grosskanzleien läuft es schon anders. Da werden Kontingente vereinbart, und es ist vorab klar strukturiert. Die Anwälte müssen schauen, ob sie es schaffen, die Arbeit innerhalb des vereinbarten Rahmens zu erledigen. Sonst verlieren sie Geld, und dann wird es spannend, weil man Tools einsetzen muss. Und wir sehen jetzt schon, dass sich das durchsetzen wird, vor allem, wenn die Mandanten das Konto nicht mehr ganz so weit öffnen. Das wird zunächst bei den Grosskanzleien beginnen, aber ich denke, das wird sich auch auf mittelständische und kleinere Kanzleien ausdehnen.
David: Der Einsatz einer KI hat viel mit Vertrauen zu tun – das wurde ja mehrfach erwähnt. Dieses Vertrauen muss aufgebaut werden. In anderen Bereichen und Industrien gibt es bereits Qualität-Prüfstandards, wie zum Beispiel den TÜV.
Würde es im Bereich KI den Nutzenden helfen, wenn es Qualitäts-Standards wie den TÜV gäbe?
Don: Da muss man unterscheiden, was genau mit Standards gemeint ist oder mit dieser Messbarkeit. Viele Standards, wie die vom TÜV, garantieren, dass ein Produkt oder eine Maschine bestimmte Sicherheitsstandards einhält, zum Beispiel dass sie ein bestimmtes Gewicht aushält. Es wäre wünschenswert, wenn es auch im Bereich der Künstlichen Intelligenz solche Sicherheitsstandards gäbe – zum Beispiel in Bezug auf Halluzinationen oder andere Sicherheitsvorkehrungen. Das würde mir helfen, ruhiger zu schlafen, wenn ich KI einsetze, weil ich wüsste, dass sie keine katastrophalen Fehler macht.
Aber das hilft mir nicht dabei, innerhalb der existierenden KI-Lösungen diejenige auszuwählen, die für meinen speziellen Use Case am besten geeignet ist. Nur weil eine KI keine katastrophalen Fehler in anderen Kontexten macht, heisst das nicht, dass sie die beste Lösung für meinen spezifischen Fall ist. Diese Standards helfen also nur bedingt oder gar nicht bei der Auswahl einer spezifischen Lösung. Dafür braucht man wieder spezifische Tests, die genau auf das eigene Problem zugeschnitten sind.
Nils: Ja, ich sehe das in Bezug auf Performance ähnlich wie Don. Ich weiss, dass Kanzleien Lizenzen zu fast allen Large Language Models haben, um damit herumzuprobieren. Ich weiss, dass sie intern schon Tests gebaut haben, wie wir es vorher besprochen haben, aber individuell für ihre jeweilige Praxisgruppe, um zu sehen, ob das funktioniert. Testing findet also bereits statt, und ich denke auch, dass man das immer noch an die individuelle Aufgabe anpassen muss. Die KI-Qualität eine gewisse Kontrolle im Rahmen spezifischer Aufgaben in Kanzleien oder Rechtsabteilungen verbessern.
Standards in Bezug auf Datenschutz und Datensicherheit sind natürlich unumgänglich – darüber brauchen wir nicht zu diskutieren. Aber die Performance für den einzelnen Use Case zu messen, ist etwas komplexer. Man könnte vielleicht eine Art Vergleichs-Website wie Check24 für die beste Vertragsprüfungs-KI erstellen, aber das müsste wirklich ganz spezifisch auf den Use Case zugeschnitten sein. Da sehe ich auch Probleme, beispielsweise: Ein allgemeiner AGB-Checker wäre problematisch zu vergleichen, weil es so viele verschiedene Anwendungsfälle gibt – etwa ein Solarunternehmen versus ein Softwareunternehmen. Wenn man ein AGB-Checker-Tool oder ein Drafting-Tool baut und dann hier die Performance messen möchte, kommt einem die grosse Bandbreite im juristischen Bereich in die Quere. Das macht es so schwierig, Standards in Bezug auf die Performance zu setzen.
Wenn ich jetzt als Nutzer*in eine AI-Lösung auswählen möchte – wie gehe ich da vor?
Gordian: Da gibt es zwei Perspektiven: Will ich eine fertige Lösung auswählen, oder möchte ich das selbst entwickeln? In beiden Fällen muss man sicherstellen, dass der Prozess, über den wir gesprochen haben, eingehalten wird. Das heisst, als Erstes muss man definieren, was der Business Case ist. Ist eine Vollautomatisierung sinnvoll, oder eher eine Unterstützung durch die KI? Wie gut muss die KI für diesen spezifischen Business Case sein?
Natürlich gibt es auch allgemeine Themen wie Datensicherheit und Genauigkeit in Bezug auf den eigenen Business Case. Wichtig ist auch, dass man das nötige Fachwissen hat, um den Business Case zu evaluieren. Man kann nicht einfach das Entwicklungsteam und das KI-Team laufen lassen. Es braucht das Know-how zum Beispiel von Anwälten, die Verträge prüfen, um genau zu wissen, wie das zu tun ist. Nur wenn die Fachabteilung und die KI-Abteilung zusammenarbeiten, kommt ein sinnvolles Ergebnis heraus.
Dasselbe gilt auch, wenn man ein fertiges Tool auswählt. Es gibt zwar bereits einige Standards wie die ISO-Zertifizierungen, aber es gibt noch keinen vollständig abgedeckten Prozess. Wenn ich einen Anbieter auswähle, würde ich eine Art Plausibilitäts-Check machen: Ich würde den Anbieter direkt fragen, wie er die Qualität sicherstellt, ob er spezifische Tests für den jeweiligen Use Case hat und ob es beispielsweise im Legal-Tech-Bereich tatsächlich Anwälte im Team gibt, die die Qualität sicherstellen können. Ein Legal-Tech-Anbieter ohne Anwalt im Team ist meiner Meinung nach nicht vertrauenswürdig. Da muss man wirklich diesen Plausibilitätscheck machen, um zu sehen, ob der Anbieter das tatsächlich leisten kann.
David: Man sollte also mit Blick auf die KI nachfragen, wie der Provider sich mit dem Thema Testsets auseinandersetzt und darauf achten, wie das Team zusammengesetzt ist – ob nur Techniker an Bord sind, nur Juristen oder eine Kombination?
Gordian: Genau. Und dieselbe Einschätzung sollte man natürlich auch intern vornehmen, wenn es ein erfolgreiches Projekt werden soll. Aber es ist genauso wichtig, dies beim Provider zu tun. Es gibt aktuell durch den Hype viele Player auf dem Markt, die relativ schnell mit wenigen Leuten und ChatGPT etwas auf die Beine stellen. Ob das dann langfristig die KI-Qualität sicherstellen kann, ist fraglich. Man muss sich anschauen, ob das Team wirklich in der Lage ist, die notwendige Leistung zu erbringen. Meiner Meinung nach kann ein Provider das nur sicherstellen, wenn er auch Fachleute im Team hat.
Nils: Da gebe ich Gordian vollkommen recht. Ein gutes Beispiel ist Harvey– die haben eine Menge Geld bekommen und das erste, was sie gemacht haben, war, Leute von Grosskanzleien auf Partnerebene abzuwerben, die das nötige Wissen haben oder zumindest auf General-Counsel-Ebene agieren können. Man braucht jemanden, der sowohl den Input als auch den Output fachlich bewerten kann. Ab einem gewissen Punkt hat keiner von uns wirklich Ahnung. Ob die Klausel in einem M&A-Vertrag passt oder nicht, weiss ich nicht. Das habe ich nie gemacht, da bin ich komplett raus, genauso wie bei Outputs aus anderen Rechtsgebieten. Da braucht man eben Experten im Team, die den Output aus juristischer Sicht bewerten können. Das ist am Ende entscheidend. Natürlich findet eine interne Evaluation auch statt, aber die Teamstruktur ist ein sehr wichtiger Punkt.
Don: Es ist wichtig, einen standardisierten Prozess zu haben, um eine KI-Lösung evaluieren zu können, damit verschiedene Lösungen vergleichbar werden. Im Prinzip kennen wir dieses Problem schon aus unserem Alltag – wir hören jeden Tag von neuen KI-Tools und fragen uns, ob wir sie nutzen sollten. Viele Leute haben ein paar Beispielanfragen vorbereitet, manchmal nur zwei oder drei, mit denen sie testen, ob die KI diese spezifischen Probleme lösen kann. Dasselbe muss man auf der Business-Ebene tun: Man muss entscheiden, was einem wichtig ist, und entsprechende Testsets zusammenstellen. Ideal wäre es, dies zu automatisieren, weil es unpraktisch ist, jedes Mal, wenn ein neues Tool herauskommt, hunderte Stunden in Annotationen, Evaluationszeit und Ressourcen zu stecken. Es ist nicht einfach, ein effizientes Protokoll zu finden, das aussagekräftige Ergebnisse liefert, aber es lohnt sich definitiv, um wettbewerbsfähig zu bleiben und schnell neue Lösungen einsetzen zu können.
David: Das läuft also im Grunde darauf hinaus, dass man Testsets erstellt – entweder selbst oder in Zusammenarbeit mit einem Provider, der das strukturiert angeht und beurteilen kann, welches Sprachmodell für welche Aufgabe am besten geeignet ist. Wenn als User keine Erklärbarkeit oder Transparenz darüber besteht, wie das Ganze angegangen wird, sollte man durchaus skeptisch werden, oder?
Don: Auf jeden Fall. Selbst wenn interne Testsets verwendet werden, muss ich auch einschätzen können, wie gut diese Testsets zu meinem Use Case passen. Wenn es beispielsweise darum geht, Klauseln zu finden, ist das ein anderer Use Case als die Beurteilung ganzer Gerichtsprozesse. Wenn ich Informationen vom Provider bekomme, sagt das allein wenig darüber aus, wie gut die Lösung meinen spezifischen Fall abdeckt.
David: Unweigerlich sehe ich hier die Herausforderung, dass das Bewusstsein dafür, was man eigentlich tun will, bei vielen Kunden, die auf der Suche nach KI-Produkten sind, oft noch gar nicht vorhanden ist. Man schaut sich einfach mal um und sieht, was es gibt, aber setzt sich nicht mit der Qualität auseinander, weil man nicht klar weiss, welches Problem man eigentlich lösen möchte. Das funktioniert so nicht. Oder seht ihr das anders?
Don: Das könnte schon auch funktionieren, wenn ich als Provider dir aufzeige: Uns ist bekannt, dass es in verschiedenen Anwaltskanzleien immer wieder dieselben Probleme gibt, und wir haben dafür eine Lösung entwickelt. Vielleicht ist das in deiner Kanzlei kein Problem und interessiert dich daher nicht, aber wir können standardisierte Lösungen anbieten.
Nils: KI ist kein Selbstzweck. Aus meiner Sicht ist KI aktuell vor allem ein Anlass für Kanzleien und Rechtsabteilungen, sich mit neuen Tools zu beschäftigen. Bisher brauchte man das vielleicht nicht, aber das sollte nicht der einzige Grund sein. Allgemein ist es für Digitalisierungsprojekte gut, sich neue Technologien einmal anzusehen und zu prüfen, ob es Einsatzmöglichkeiten gibt. Aber das sollte nicht auf Teufel komm raus geschehen. Wenn ich einen konkreten Use Case habe, sollte ich mir zuerst überlegen, wo es in meinen Prozessen Sinn ergibt, KI einzubinden. Blind etwas zu kaufen, nur weil alle anderen es tun, halte ich nicht für sinnvoll. Manchmal wird das von FOMO (Fear of Missing Out) getrieben, nur weil es andere auch machen. Es ist besser, Zeit und Geld gezielt zu investieren.
David: Vielen Dank für die interessanten Ausführungen - herzlichen Dank an Nils, Don und Gordian!
{% video_player "embed_player" overrideable=False, type='hsvideo2', hide_playlist=True, viral_sharing=False, embed_button=False, autoplay=False, hidden_controls=False, loop=False, muted=False, full_width=False, width='1920', height='1080', player_id='177587928222', style='' %}Erfahren Sie, wie Legartis Ihre Vertragsarbeit mit KI beschleunigt.

Publikumsfragen
Wie viel schneller ist man, wenn die KI die Vorarbeit macht, beispielsweise bei der Vertragsprüfung, und diese Vorarbeit dann manuell korrigiert wird?
Gordian: Ja, das ist eine sehr gute Frage. Es geht genau in die Richtung, die wir bereits diskutiert haben. Der Einsatz von KI, wie wir ihn zum Beispiel bei Legartis in der Vertragsprüfung sehen, bedeutet, dass die KI als Assistenzlösung dient. Sie hilft dabei, die Arbeit schneller zu erledigen. Wir schauen uns genau an, wie viel Zeit eine manuelle Prüfung braucht und wie viel Zeit eine Prüfung mit KI benötigt. In den meisten Fällen ist man mit KI deutlich schneller und hat gleichzeitig eine reduzierte Fehlerrate.
David: Es gibt auch Anwendungsfälle wie die Due Diligence. Wenn man 1000 Verträge nach bestimmten Fragen durchsuchen muss, dauert das unweigerlich länger, wenn man es manuell macht, als wenn man eine Legal AI für Legal Analytics dafür einsetzt. In diesem Kontext kann die KI wirklich grossartige Vorarbeit leisten.
Wie ist die Haftung geregelt, wenn KI Fehler macht und welche Konsequenzen könnten daraus entstehen?
Nils: Die Frage ist allgemein formuliert, aber im Grundsatz würde ich sagen: Wenn ich als Anwalt einen Schriftsatz herausgebe, ist es letztlich egal, wie dieser Schriftsatz erstellt wurde – ob ich ihn selbst verfasst habe oder eine KI dafür genutzt wurde. Sobald ich meinen Namen darunter setze und das Dokument unter meinem Namen verschicke, hafte ich dafür. Daher ist es bei Fehlern der KI im Grunde genauso wie bei allen anderen technischen Tools, die ich vorher nutze. Es gibt generell die Möglichkeit, sich gegen Fehler abzusichern, aber es kommt auch darauf an, wie die KI verwendet wird und welches Tool genutzt wird. Aber grundsätzlich würde ich sagen: Bei der reinen Erstellung von Schriftsätzen, sei es rund um Verträge oder Ähnliches, bleibt die Haftung letztlich beim Anwalt, der seine Unterschrift darunter setzt.
Gibt es Parallelen zur Fehlertoleranz beim autonomen Fahren? Sind wir gegenüber Fehlern von Menschen toleranter als gegenüber Fehlern von KI-Tools?
Don: Das ist gar nicht so einfach zu beurteilen. Beim autonomen Fahren gibt es ja diese klassischen ethischen Dilemmas. Da haben sich einige Autohersteller schon weit aus dem Fenster gelehnt, mit Fragen wie: "Wenn das Auto auf einen Fussgänger zurast, was mache ich dann? Kann ich rechtzeitig bremsen, oder fahre ich in eine Wand und gefährde den Fahrer?" Das sind heftige Probleme. Die Frage ist: Sind Klienten toleranter gegenüber Fehlern von Anwälten als gegenüber Fehlern von KI? Das kann ich nicht direkt beurteilen, weil ihr, Gordian und Nils, wahrscheinlich mehr Kundenkontakt habt und das vielleicht besser sagen könnt – wie die Leute reagieren, wenn die KI oder die Lösungen, die wir präsentieren, Fehler machen.
Gordian: Es ist nicht einfach zu beantworten, aber ich sehe schon Parallelen. Kunden sind tendenziell kritischer gegenüber KI, weil die Fehler oft sichtbarer sind als die von Menschen. Wenn ein Junior-Anwalt einen Fehler macht, sieht man das nicht immer sofort. Aber bei der KI sind die Fehler direkt ersichtlich.
Nils: Ich sehe das ähnlich. Anwälte und juristische Fachkräfte sind allgemein sehr kritisch gegenüber dem Output von Softwarelösungen, was gut, aber auch manchmal anstrengend für uns als Anbieter ist. Letztlich ist eine gesunde Skepsis nicht verkehrt, besonders wenn wir uns zunehmend auf autonomere Systeme verlassen. Es ist wichtig, dass sich alle mit KI beschäftigen, um zu verstehen, wo die Fehler liegen könnten und wie man sie behebt. Dadurch wird das Verständnis breiter. Zu verstehen, dass der Fehler nicht zwingend bei der KI liegt, sondern beispielsweise an der fehlenden Datengrundlage, weil ich die nicht beschafft habe, weil in meinen Dokumenten etwas unvollständig ist. Das zu verstehen und nicht einfach nur blinde Skepsis zu haben, sondern mit Hintergrundwissen zu verstehen, wo der Fehler liegen kann, finde ich sehr, sehr wichtig.Ich glaube, da wird sich auch noch einiges tun. Die Lösungen werden besser, weil durch das Feedback natürlich auch die Anbieter davon lernen und entsprechend ihre Systeme verbessern können.
Erfahren Sie, wie Legartis Ihre Vertragsarbeit mit KI beschleunigt.
Entdecke weitere Insights
Weitere relevante Inhalte zu diesem Thema

ChatGPT für Anwälte: 7 Prompts zum Testen
Chat GPT und Large Language Models im rechtlichen Kontext

“Jeder sollte sich mit LegalTech beschäftigen, ehe er von der Entwicklung abgehängt wird”
Starte heutemit Legartis!
Talk to us about your business case or test Legartis right away!